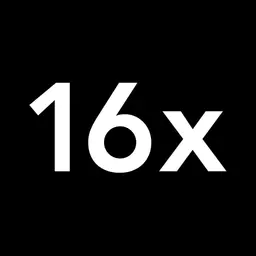
Update on 12 September: New OpenAI o1 Models Solve the Counting Problem
Since this article was first published, OpenAI has released new o1-preview models that can accurately solve the "strawberry" counting problem and other complex reasoning tasks. A new section has been added to this article towards the end to discuss these new models and their capabilities.
The Curious Case of ChatGPT's R-Counting
Large language models (LLMs) like ChatGPT, despite their impressive abilities, sometimes stumble on seemingly simple questions. One example is the AI's inability to correctly count the number of 'R's in the word "strawberry". When asked this simple question, ChatGPT often gives the wrong answer, saying there are two 'R's, when there are actually three.
This error in AI output may seem trivial, but it reveals interesting aspects of how current AI models process and understand text. It provides insight into the inner workings of these systems and highlights the differences between human and machine text comprehension.
The Secret Behind the Mistake: Model Tokenization
The main cause of ChatGPT's 'R'-counting error lies in a fundamental process called tokenization. Tokenization is how large language models break down text into smaller, manageable units for processing.

These units, called tokens, are the building blocks that the model uses to understand and generate text. Tokenization allows for efficient text processing. However, it can sometimes lead to unexpected results in AI output. The "strawberry" example demonstrates this.
Breaking Down "Strawberry": A Tokenization Example
To understand how tokenization affects ChatGPT's interpretation of the word "strawberry", let's look at the breakdown of the word as seen by the model.
When processed by GPT-4's tokenizer, "strawberry" is split into three distinct parts: [str, aw, berry].
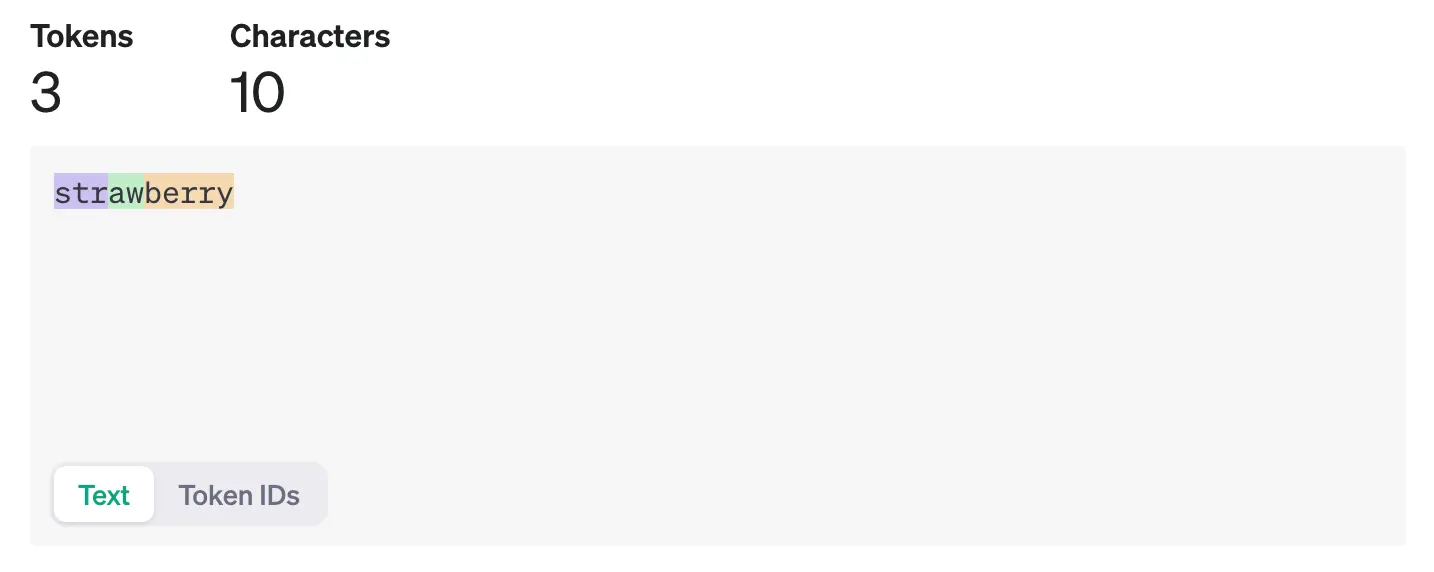
You can also see the exact token IDs for each part of the word "strawberry" below:
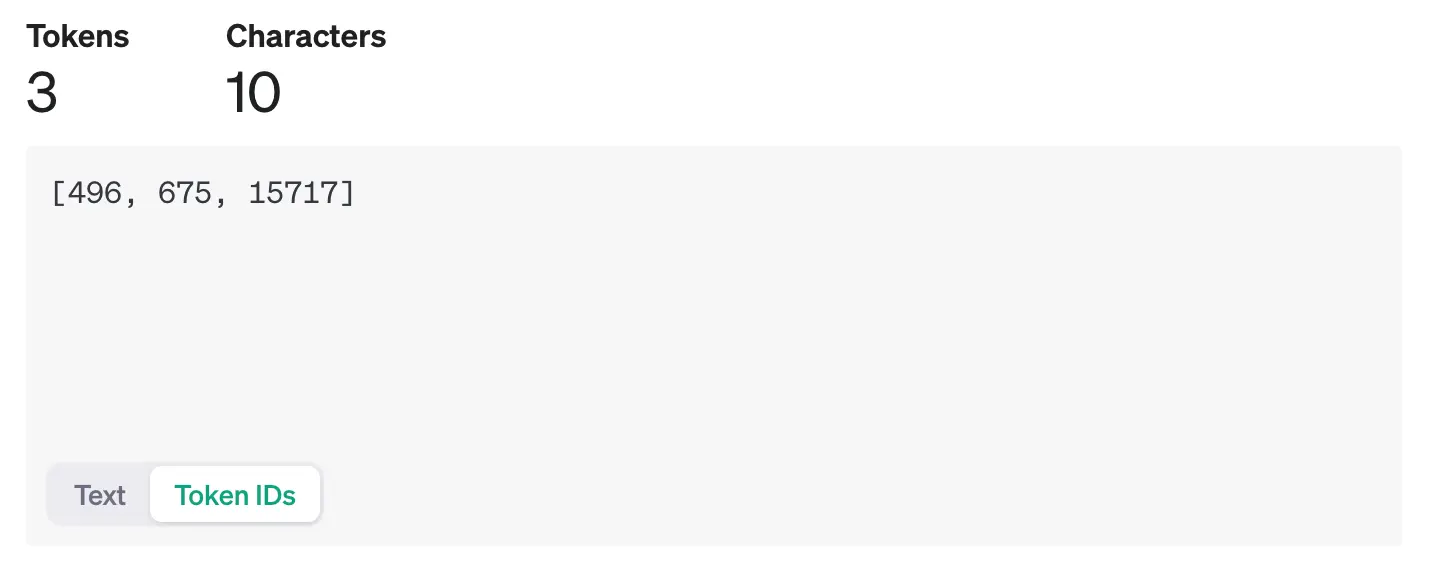
From the AI's perspective, "strawberry" is not a sequence of individual letters, it is also not a series of strings [str, aw, berry], but rather a sequence of token IDs [496, 675, 15717].
This tokenization approach is efficient for many tasks. However, it can cause problems when the model needs to analyze text at the letter level.
In the "strawberry" example, the model is unable to correctly count the 'R's because it is not processing the individual letters. It is simply processing the sequence of 3 token IDs (496, 675, 15717).
This is analogous to ask someone who does not speak Chinese to count the number of stroke in the Chinese character for "love". Since the person do not know the Chinese, or how to write the Chinese character for "love", it is impossible for the person to do it.
It is worth noting that tokenization can vary between different language models and tokenizers. Try the tokenization tool below to see how different words are tokenized by the model:
Implications for AI Language Understanding
This simple example of miscounting 'R's in "strawberry" reveals a fundamental difference between human and AI text processing. While humans naturally read and understand text at the letter level, current AI models like ChatGPT work with tokenized units that may combine multiple letters or even entire word parts.
Understanding these differences is crucial for effectively using and understanding AI outputs. It reminds us that while these large language models are incredibly powerful, they don't "think" or process information in the same way humans do. This can sometimes result in unexpected or wrong answers to seemingly simple questions.
New OpenAI o1 Models: Solving the Counting Problem
Recent developments in AI technology are addressing the limitations of traditional language models. OpenAI's new o1-preview models, released on September 12, 2024, mark a significant advancement in AI reasoning capabilities. These models are designed to spend more time thinking through problems before responding, much like a human would.
The o1-preview models can solve complex tasks that previous models struggled with, including accurately counting letters in words. This means they can correctly determine that there are three 'R's in "strawberry", overcoming the tokenization barrier that hindered earlier models.

By learning to refine their thinking process, try different strategies, and recognize their mistakes, these new models demonstrate a more sophisticated understanding of language at a granular level.
This breakthrough not only solves the "strawberry" counting problem but also opens up new possibilities for more complex reasoning tasks in various fields.
In tests, these models have shown remarkable performance in challenging areas such as physics, chemistry, biology, math, and coding. For instance, in a qualifying exam for the International Mathematics Olympiad (IMO), the new model scored 83%, compared to GPT-4o's 13%.
Managing Tokenization with 16x Prompt
While ChatGPT's tokenization can lead to unexpected results in simple tasks like counting letters, it becomes even more crucial when dealing with complex coding tasks. 16x Prompt offers features that help developers handle these tokenization challenges effectively, such as real-time token limit tracking and a code context management system.
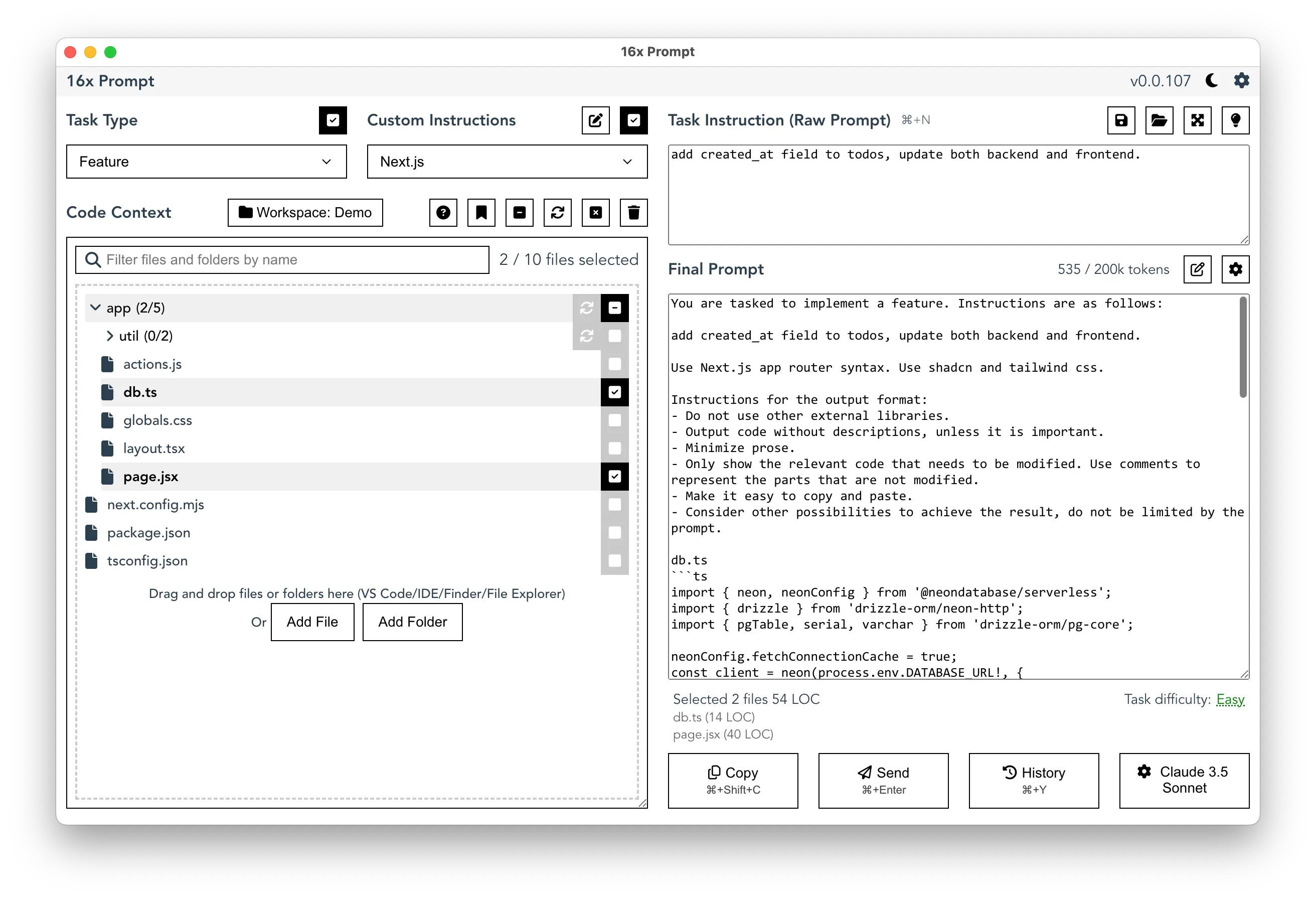
These features allow developers to optimize their token usage by focusing on the most relevant code segments. This reduces the risk of hitting token limits or receiving truncated responses. By providing detailed control over which parts of the codebase are included in the prompt, 16x Prompt enables more efficient and effective communication with AI models.