What is a token calculator?
A token calculator is a tool designed to estimate the number of tokens used in text inputs for large language models (LLMs) like Anthropic Claude and OpenAI GPT-4o. It calculates the prompt tokens and API cost for a given text input.
It helps users understand and manage their token usage when working with these models through API calls.
Why is token calculation important?
Token calculation is crucial because:
- It helps estimate API costs
- It ensures you stay within the model's context window limits
- It allows for better planning and optimization of AI-powered applications
What is the input limit (context window)?
The context window (context limit) represents the maximum token limit an AI model can process as input. It is the maximum input limit for the model to generate a response.
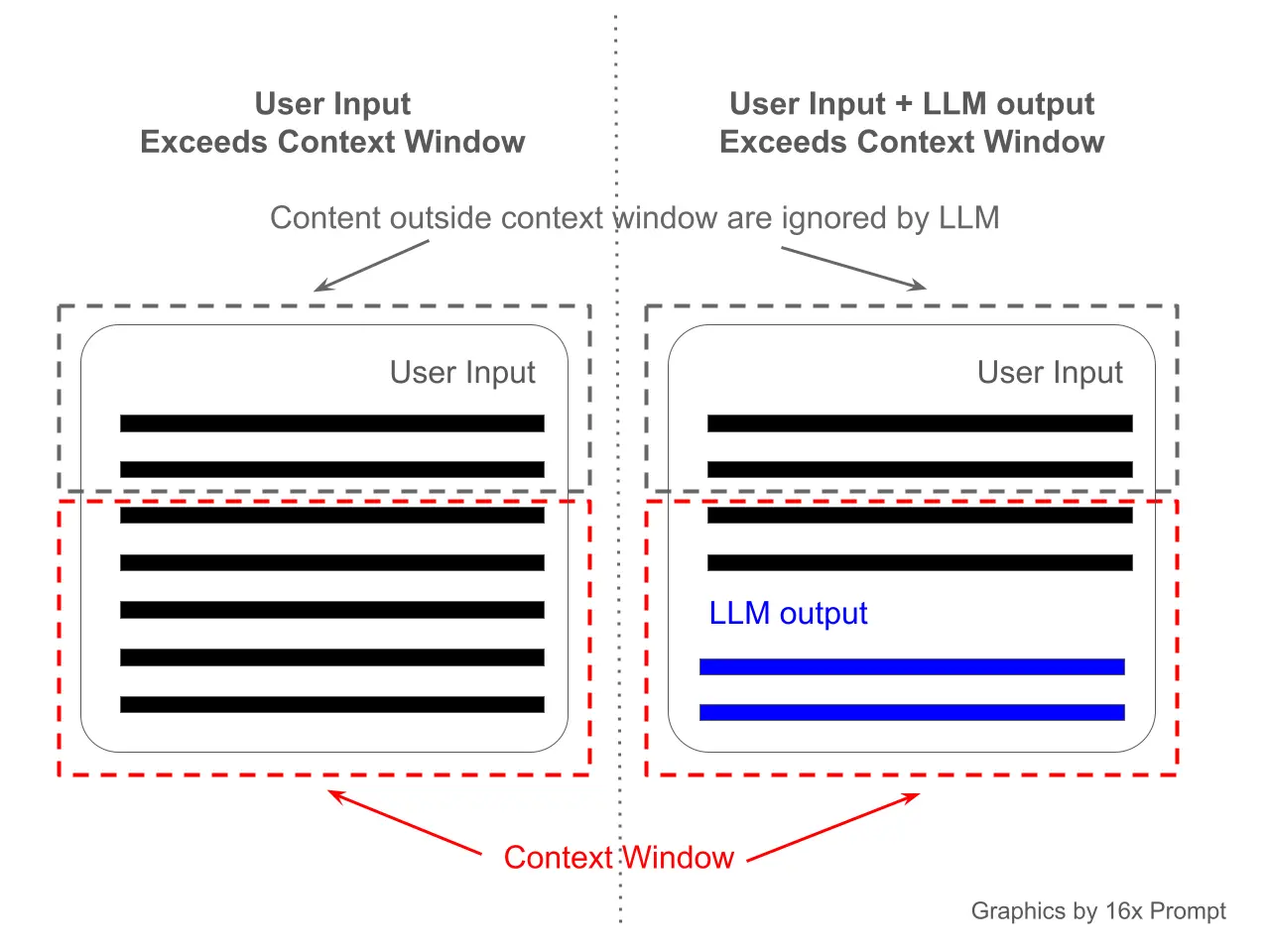
What's the maximum input token limit for GPT-4o?
The maximum input token limit (context window) for GPT-4o is 128k tokens.
What's the maximum input token limit for Claude 3.5 Sonnet?
The maximum input token limit (context window) for Claude 3.5 Sonnet is 200k tokens.
What's the maximum output token limit for GPT-4o?
The maximum output token limit for GPT-4o is 4096 tokens.
The new GPT-4o Long Output model has a maximum of 64K output tokens per request.
What's the maximum output token limit for Claude 3.5 Sonnet?
The maximum output token limit for Claude 3.5 Sonnet is 8192 tokens.
Recently Anthropic has released a new beta for Claude 3.5 Sonnet with 8192 output tokens:
8192 output tokens is in beta and requires the header anthropic-beta: max-tokens-3-5-sonnet-2024-07-15. If the header is not specified, the limit is 4096 tokens.
What AI models does this calculator support?
This token calculator supports latest models like:
- GPT-4 Turbo
- GPT-4o
- GPT-4o Long Output
- GPT-4o mini
- o1-preview
- o1-mini
- Claude 3.5 Sonnet
Newly released models are also added to the calculator as they become available.
How accurate is the token count provided by the calculator?
The calculator is based on the package @xenova/transformers, which provides accurate token counts for various AI models.
The underlying tokenizers are from Hugging Face, including Xenova/gpt-4o and Xenova/claude-tokenizer.
How can I use this calculator to manage my API spending?
By estimating token usage before making API calls, you can:
- Set appropriate spending limits
- Optimize your prompts for efficiency
- Choose the most cost-effective model for your needs
What's the difference between GPT-4o and Claude 3.5 Sonnet in terms of token usage?
Based on the JavaScript React sample of 349 lines provided:
- GPT-4o uses 2518 tokens for the given input
- Claude 3.5 Sonnet uses 2776 tokens for the same input
This difference in token count can affect both performance and cost.
How do I interpret the input and output costs shown in the calculator?
The input and output costs represent:
- Input cost: The cost if the tokens are the input provided to the AI model by the user
- Output cost: The cost if the tokens are the output generated by the AI model in response to the user's input
These costs help you estimate the total expense for each API call.
Can I use this calculator for other language models?
Currently, the calculator is designed specifically for GPT-4 Turbo, GPT-4o, GPT-4o mini, and Claude 3.5 Sonnet. For other models, you may need to refer to their specific documentation for accurate token counting methods.
How can I optimize my prompts to reduce token usage?
To optimize token usage:
- Be concise in your prompts
- Remove unnecessary context or repetitive information
- Use more efficient language and formatting
- Break down large tasks into smaller, manageable chunks
Does the calculator work for different programming languages?
Yes, the calculator can estimate token usage for various programming languages. The example shows samples for JavaScript React and Python Django, but it should work for any text input.
How can I manage the context window and token limit effectively?
Using a workflow automation tools like 16x Prompt can help streamline the process of breaking down inputs and managing the context window and token limit effectively: