On November 12th, 2024, the latest series of code-specific Qwen model, Qwen2.5-Coder-32B-Instruct was released by the Alibaba Cloud Qwen Team. The model aims to match GPT-4's coding abilities. It's also small enough to run locally on computers with more than 32GB RAM.
Promising Benchmark Results
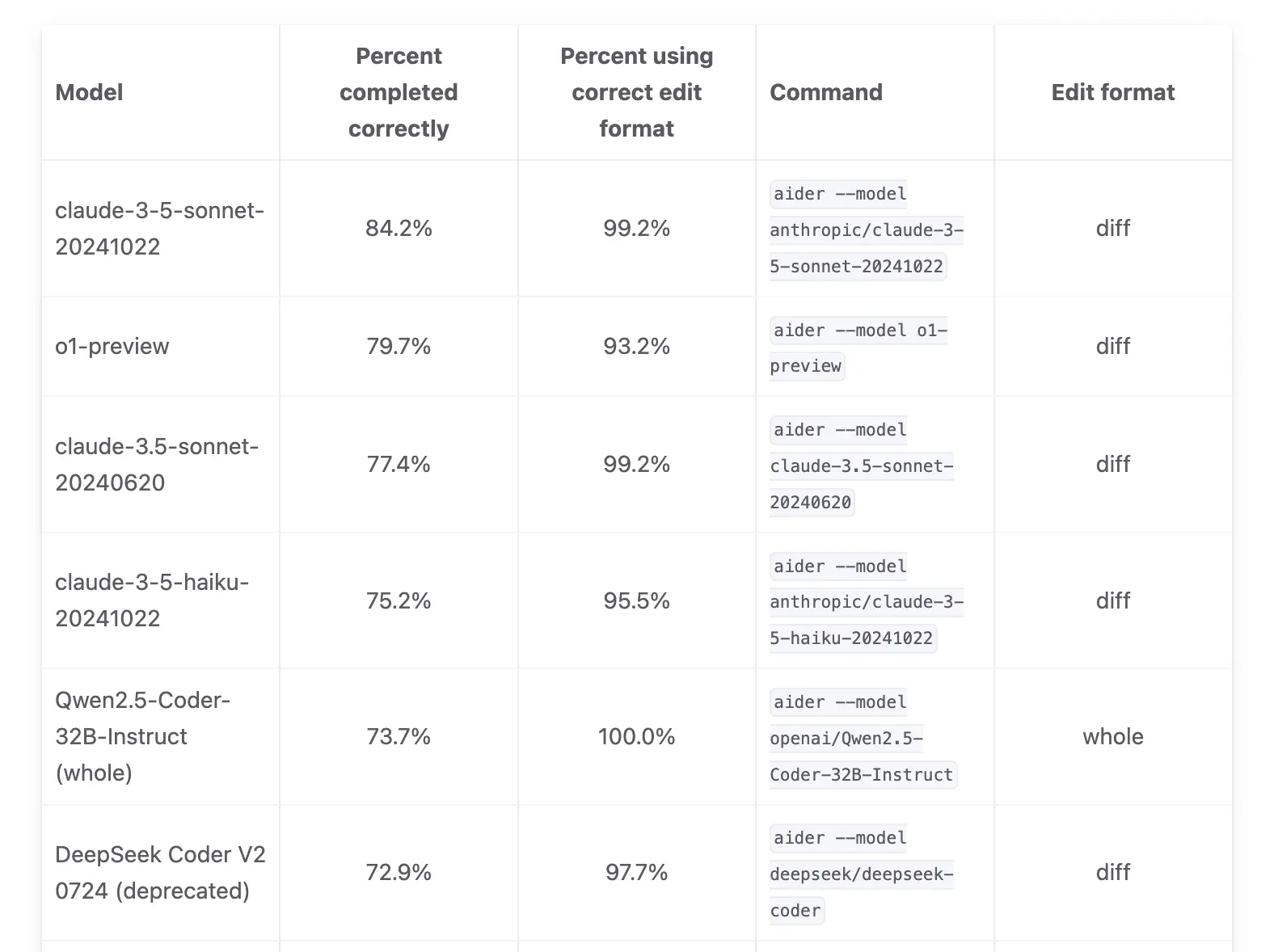
The new model has achieved impressive results on multiple industry benchmarks according to published performance metrics. It currently ranks 4th on Aider's code editing benchmark with a score of 73.7%, behind only Claude 3.5 Sonnet and similar top-tier models.
The model shows impressive performance in code generation and reasoning across multiple programming languages, scoring 65.9 on the McEval benchmark.
Notable Features
The model brings several new features to local development. It can run on computers with more than 32GB RAM, making it possible to use for individual developers and small teams without relying on cloud services.
The model supports over 40 programming languages. It demonstrates advanced code reasoning capabilities and robust code generation features, making it a good option compared to cloud-based coding tools. The Apache 2.0 license allows for broad commercial use and changes, making it one of the best open-source models.
Practical Code Generation
Testing by Simon Willison shows the open-source model is good at practical coding tasks like making data scripts and visual outputs. It works especially well with standard library code and terminal-based graphics.
It can handle many types of programming tasks, from database work to creative coding like making fractals. Running these complex tasks locally while keeping good quality makes it useful for daily development work and code completion.
Context Window Limitations
A big challenge reported by multiple developers on Reddit is the model's output becoming nonsense when hitting context limits. This happens most often when using tools that limit the context length to 33K tokens instead of the full 128K.
This context window limit seems to be a core issue rather than random errors. Users with different tools report the model breaking down into nonsense after certain context limits, requiring careful management of input size.
Local Deployment
The model runs well on home computers, generating about 10 tokens per second on 64GB MacBook Pro M2 according to testing.
When using MLX on Apple Silicon, it uses around 32GB memory, making it work well for developers with better machines.
Looking Ahead
While large language models Qwen 2.5 Coder shows promise for local coding help and real-world applications, developers should check if it fits their needs. The model is an important step toward AI coding tools that run on your computer.
The open source nature and good benchmark scores suggest this could become a useful tool for developers who want alternatives to cloud tools. But its success depends on fixing current issues with context handling and consistency.
Getting Better Results with 16x Prompt
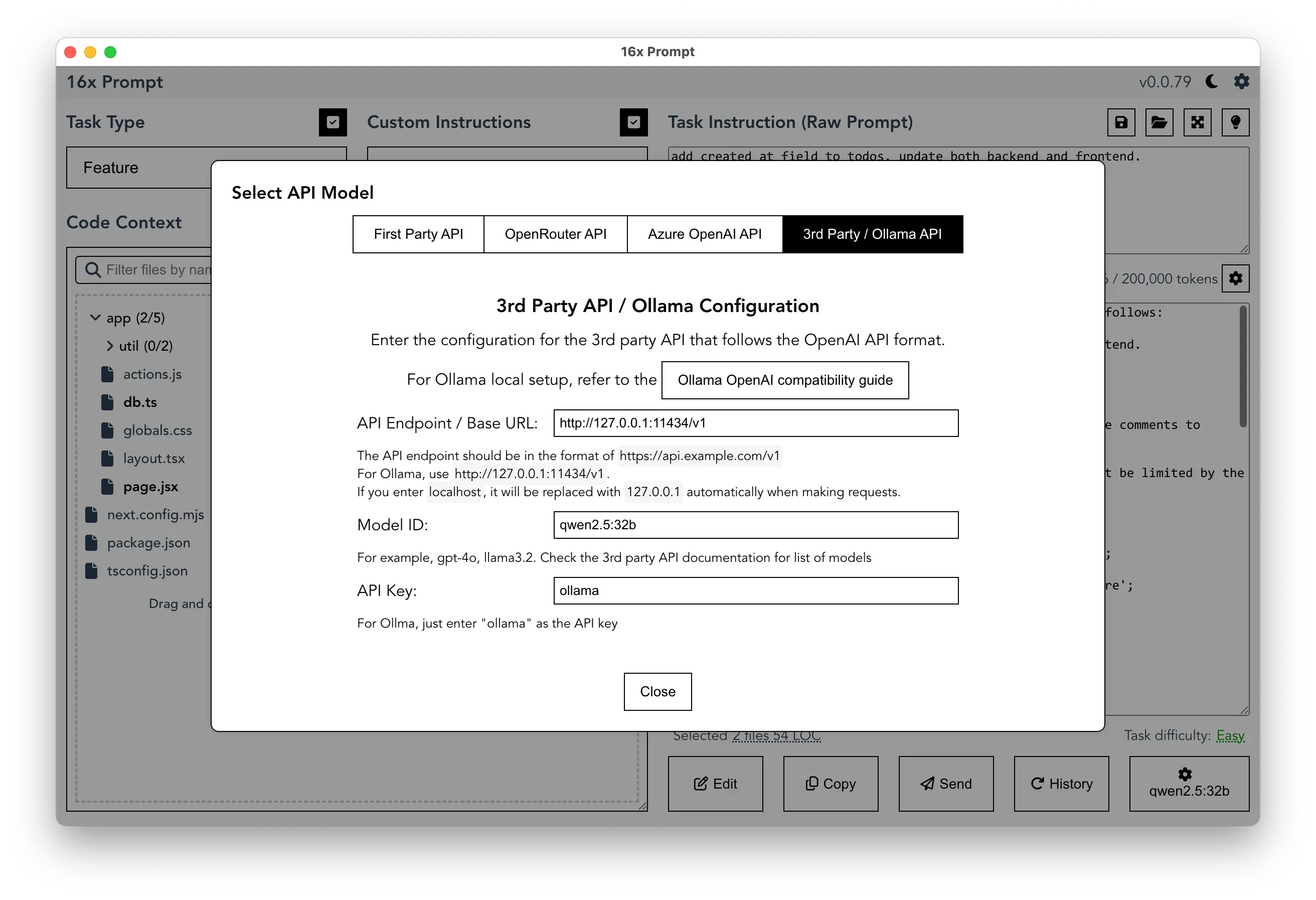
Tools like 16x Prompt can help developers manage source code context in existing projects. Its code context management system uses a tree structure that makes handling complex codebases more efficient, especially important given Qwen's context window limitations.
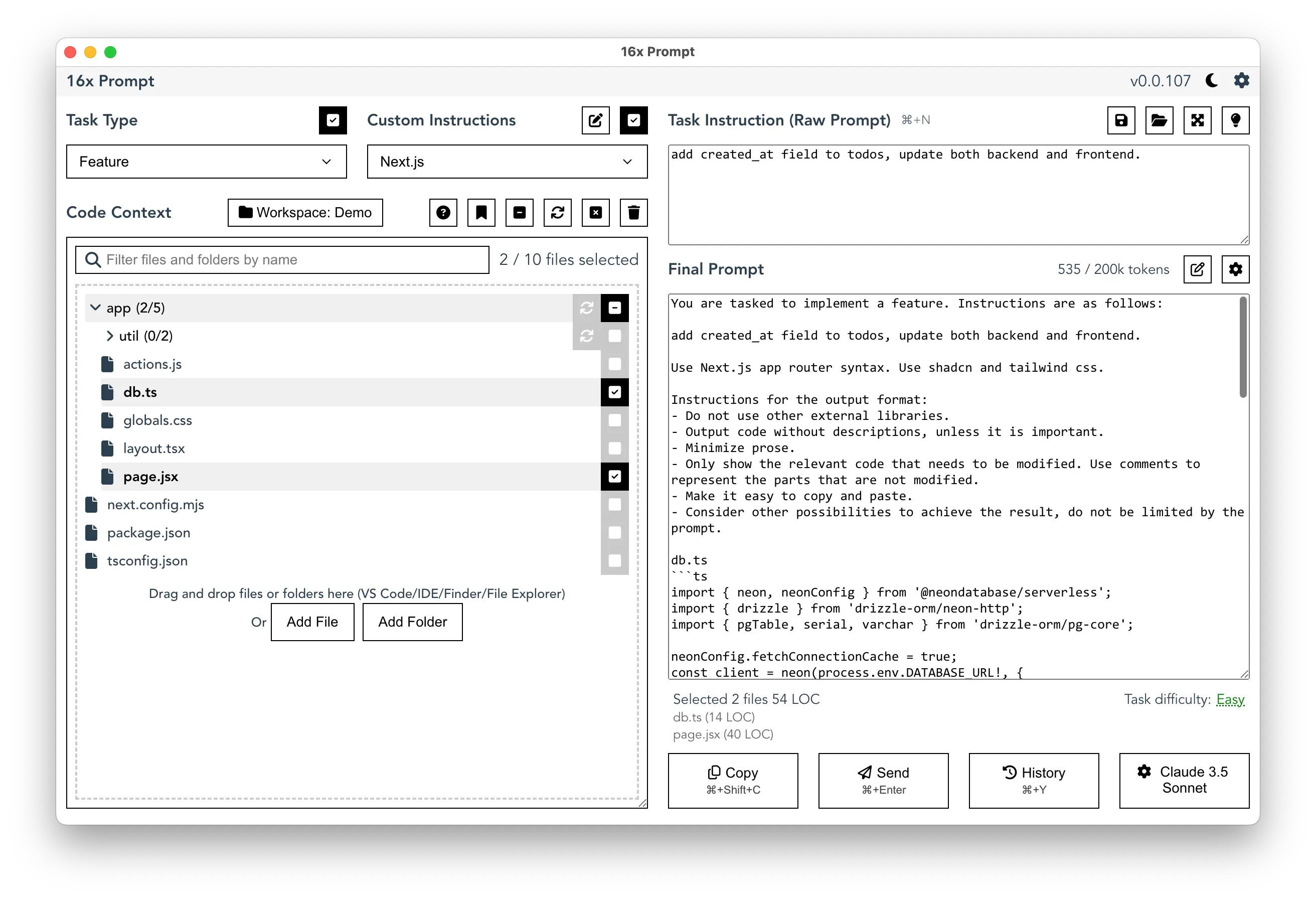
The app provides flexibility in model selection, allowing developers to compare responses from different AI models side by side. This feature is particularly useful when evaluating Qwen 2.5 Coder against other models for specific coding tasks.
For developers concerned about privacy and data security, 16x Prompt can work locally without internet connection. This aligns well with Qwen 2.5 Coder's local deployment capabilities, creating a fully offline development environment.
Here's an example screenshot of setting up 16x Prompt to use Qwen 2.5 Coder 32B via Ollama locally: