With the recent release of Claude 3.7 Sonnet on 25 February 2025, developers are testing its performance against the proven Claude 3.5 Sonnet for coding tasks. Let's look at the key differences and experiences from the developer community.
Initial Excitement with Claude 3.7 Sonnet
On the day of the release (25 February), developers were excited about Claude 3.7 Sonnet's capabilities. According to Reddit user Ehsan1238, Claude 3.7 showed impressive abilities with complex code. The model could complete in one go what typically took days of work.
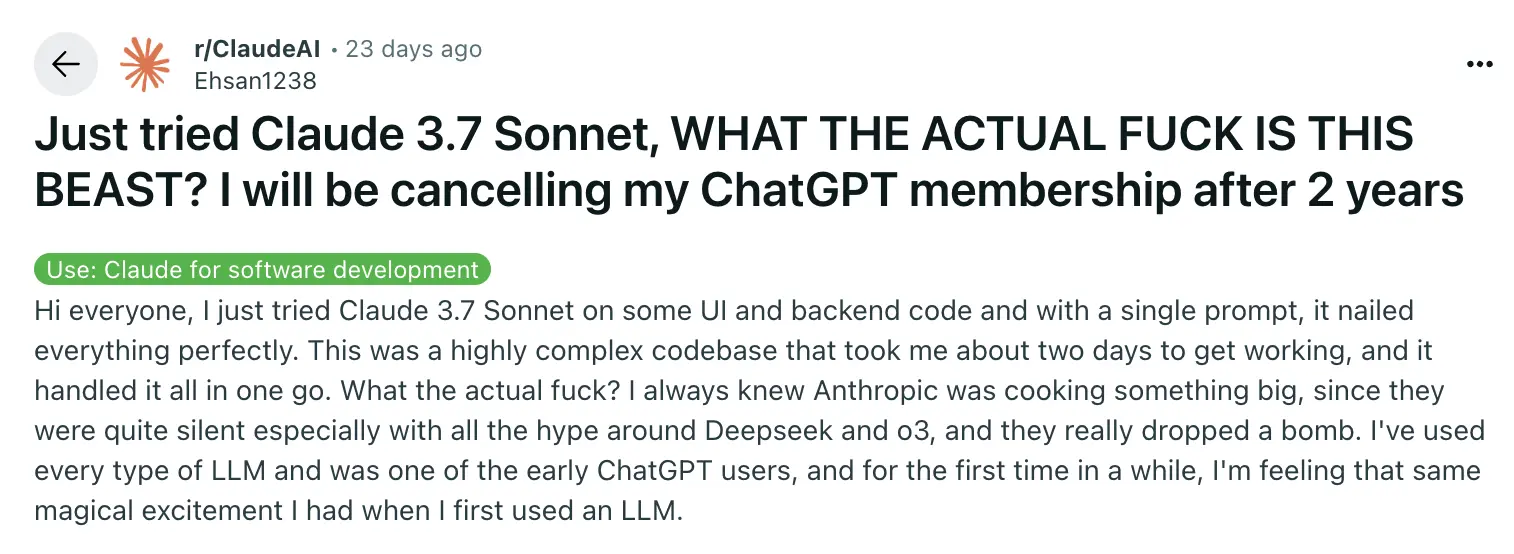
The model shows particular strength in handling complex UI and backend code at the same time. This ability suggests big improvements in understanding and creating complex system designs.
Claude 3.7 Sonnet Over Engineering
However, as more developers started using Claude 3.7, some noticed issues with the model.
@thekitze on X illustrated the difference between versions 3.5 and 3.7, showing how 3.7 tends to be overenthusiastic and goes beyond the original request.
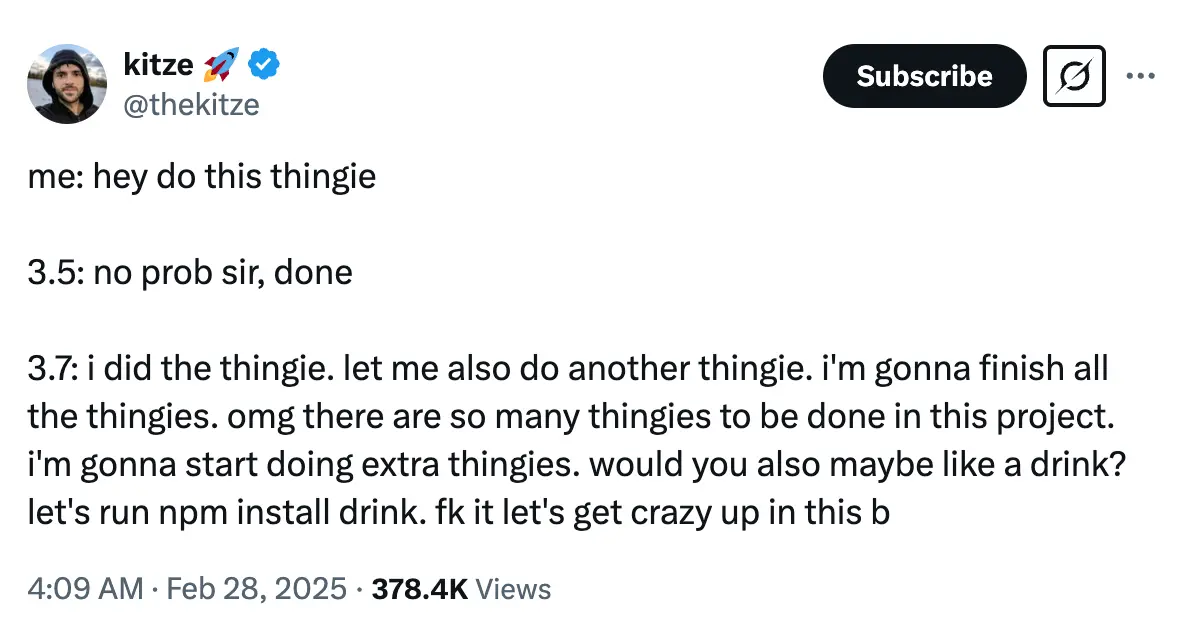
While 3.5 simply completes the task, 3.7 adds extra features and even suggests unrelated improvements.
Claude 3.7 Sonnet Unable to Follow Instructions
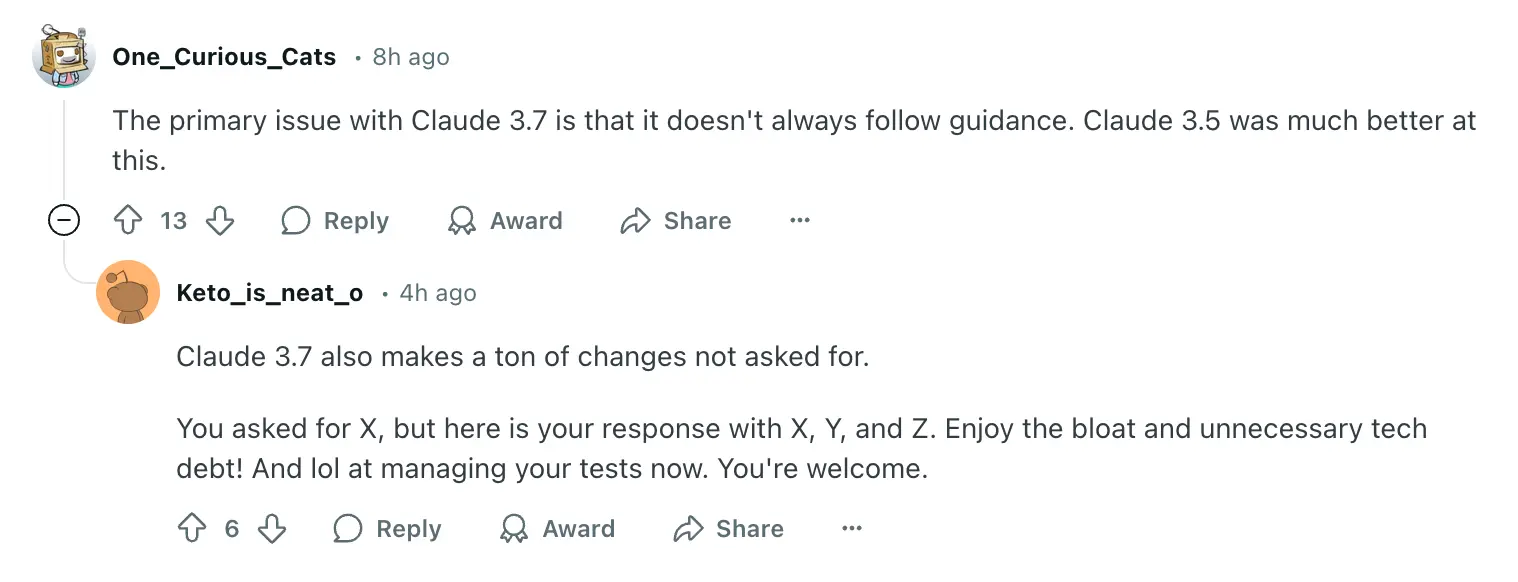
According to Reddit user One_Curious_Cats's comment, Claude 3.7 Sonnet is unable to follow instructions as closely as 3.5 Sonnet.
The primary issue with Claude 3.7 is that it doesn't always follow guidance. Claude 3.5 was much better at this.
Comparison of Claude 3.5 and 3.7
For everyday coding tasks, some developers still prefer Claude 3.5 Sonnet. According to developer @mayfer on X / Twitter on 20 March, Claude 3.5 Sonnet is still better than Claude 3.7 Sonnet for coding tasks.
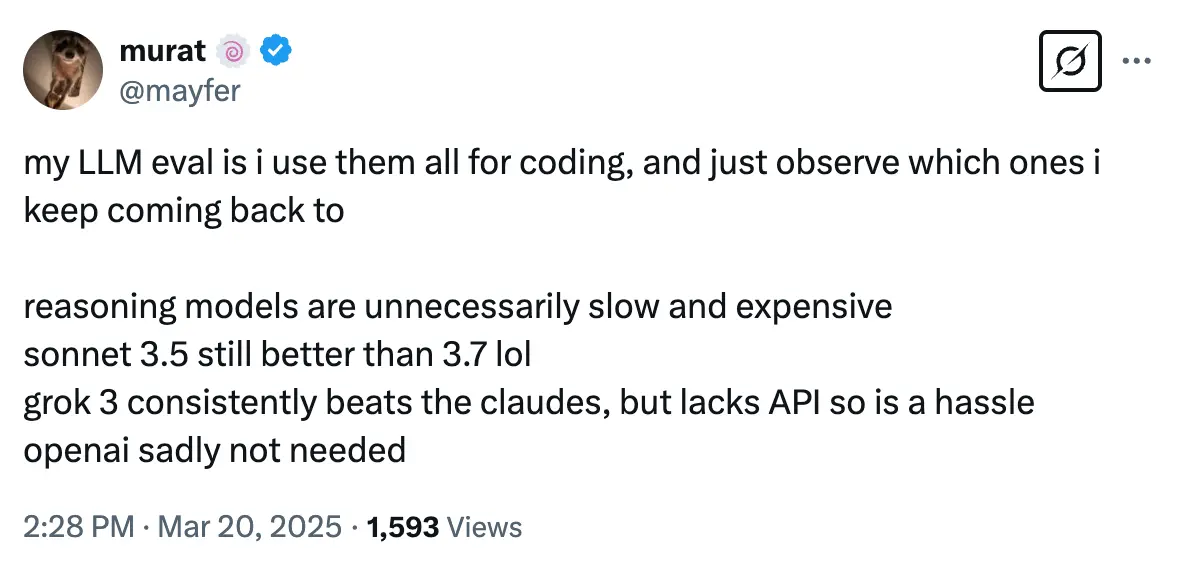
Other new models like o1 are "not good as a daily tool".

Similarly, @SeifBassam on X shared that he went back to Claude 3.5 Sonnet after using 3.7 for a while and found it to be better.
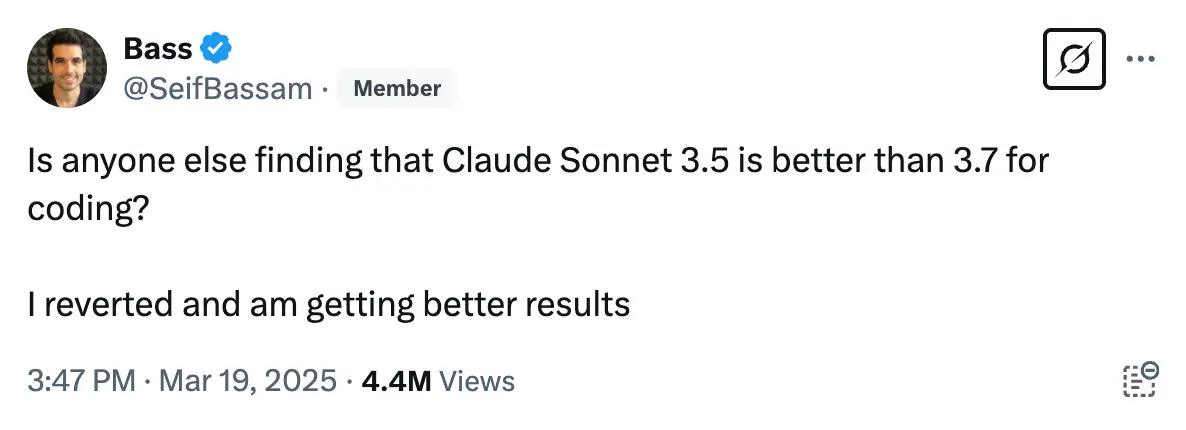
The consensus from X / Twitter is that Claude 3.5 Sonnet is better than 3.7 for coding.
Human Evaluated Coding Benchmark
A recently released human evaluated coding benchmark called KCORES LLM Arena compared the performance of top LLMs on a set coding tasks and used human evaluators to score the results against a set of evaluation criteria.
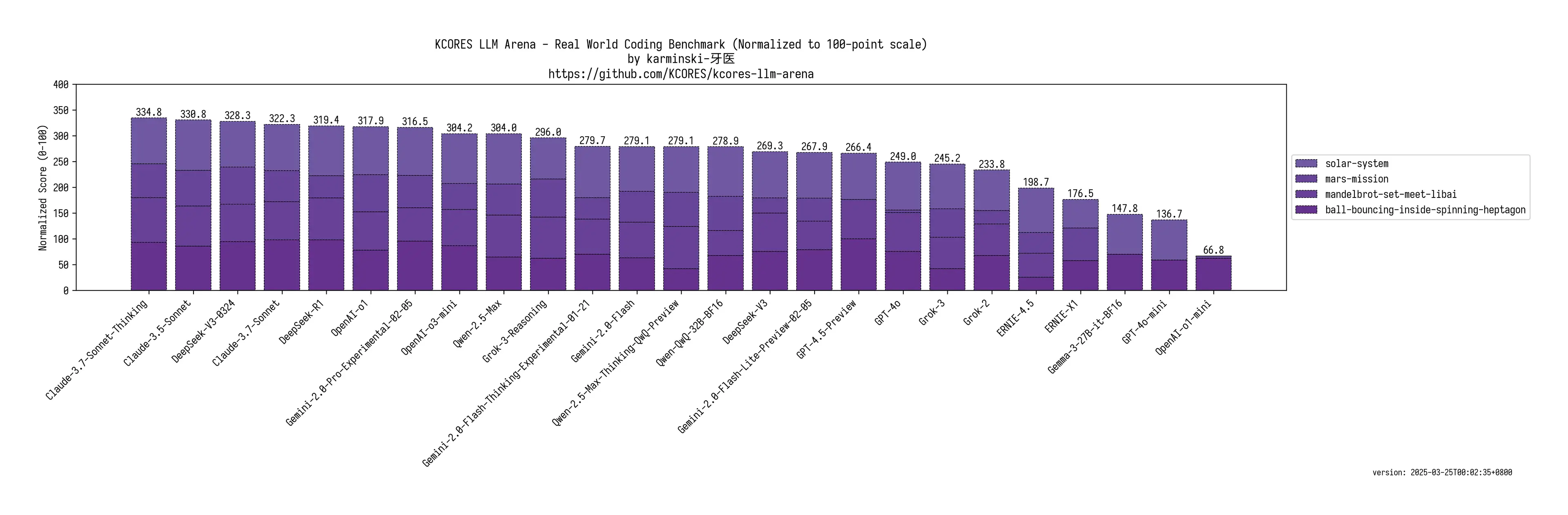
The results are as follows:
- 1st place: Claude 3.7 Sonnet Thinking - 334.8
- 2nd place: Claude 3.5 Sonnet - 330.8
- 3rd place: DeepSeek-V3-0324 (New version) - 328.3
- 4th place: Claude 3.7 Sonnet - 322.3
This shows that Claude 3.5 Sonnet is better than the non-thinking version of Claude 3.7 Sonnet, but worse than Claude 3.7 Sonnet Thinking. However, this benchmark is focused on coding new projects, and the results may not be representative of the performance of the models in existing projects.
3.7 Unstoppable Chain of Actions
Some developers have reported issues with Claude 3.7's tendency to continue modifying code beyond the original request. According to Reddit user stxthrowaway123 who posted the observation in Cursor subreddit, Claude 3.7 can be "basically unusable" due to its inability to stop its chain of actions:
It's like it has no ability to stop its chain of actions. It will attempt to solve my original prompt, and then it will come across irrelevant code and start changing that code, claiming that it has found an error. At the end of its actions, it has created a mess.
This behavior has led some developers to switch back to Claude 3.5, which they find more focused and controlled in its responses.
Taming Claude 3.7 Sonnet
To get the best results from Claude 3.7, Reddit user Old_Round_4514 suggests starting slow and being very clear with instructions.

It's best to go with the flow and work with the model. Check the output after letting the model do its work:
Enjoy that ride rather than fight it and you will get the best out of it, not always, but when its good its very very good.
According to Reddit user vanderpyyy's post, the model tends to make things too complex.

A helpful fix is adding "Use as few lines of code as possible" to custom instructions. This simple change has led to much better and simpler code outputs.
Recommendations for Developers
For most coding tasks, Claude 3.5 Sonnet seems to be the more reliable choice. It gives more consistent results and needs less prompt engineering to work well.
Use Claude 3.7 Sonnet for complex design tasks or when you need new ideas for tough problems. But be ready to spend more time writing clear prompts and managing the model's tendency to make things complex.
An alternative approach is to use Claude 3.7 Sonnet Thinking for complex design tasks and Claude 3.5 Sonnet for actual coding and implementation. This is similar to what deepclaude does, but with Claude 3.7 Sonnet Thinking as the thinking model instead of DeepSeek R1.
Tools for Optimizing Claude
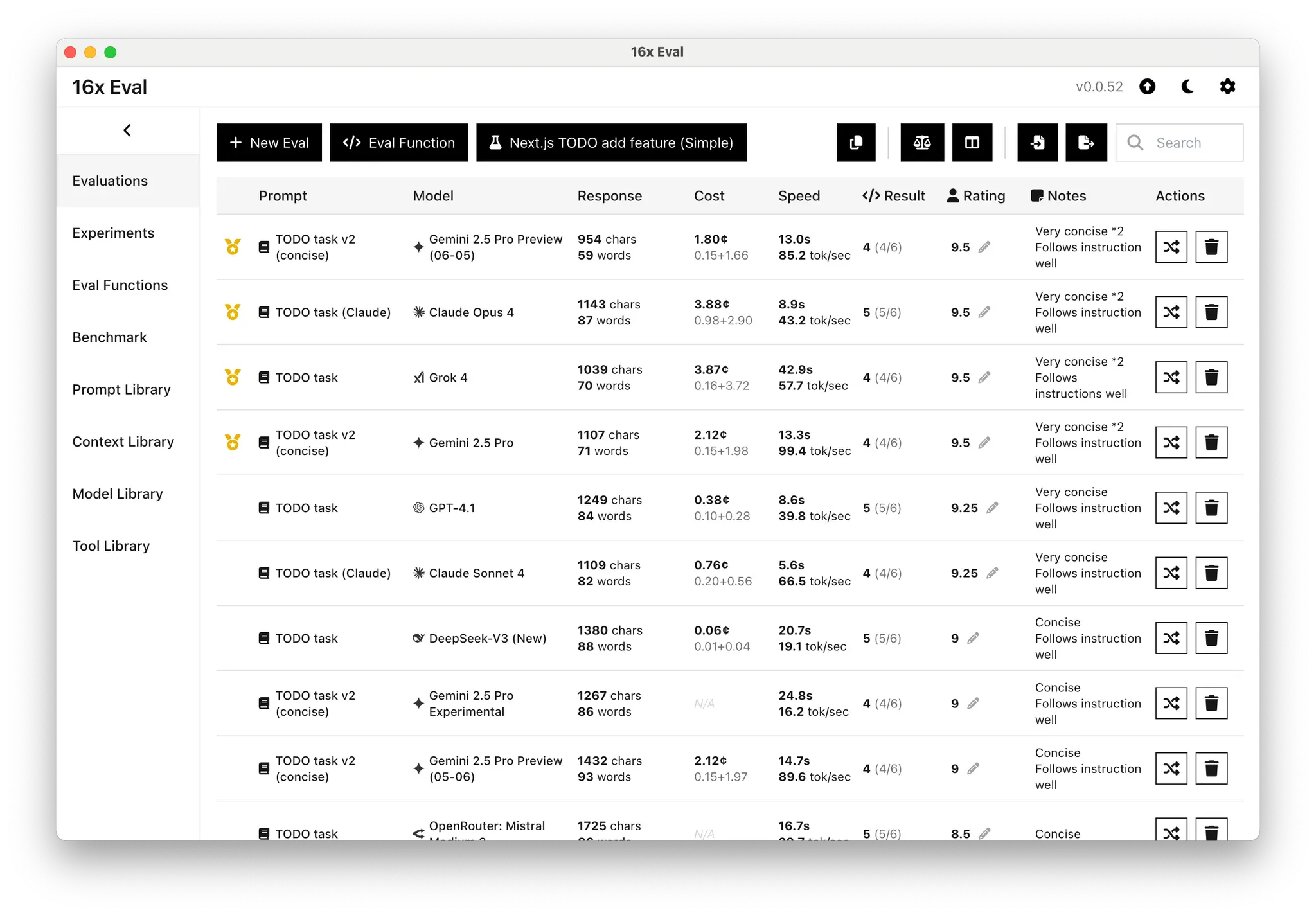
Tools like 16x Prompt can help you get better results from Claude 3.5 or 3.7 Sonnet. The app has features to help you manage code context and built-in custom instructions specific to Claude 3.7 Sonnet.
You can also use 16x Prompt to compare the responses of Claude 3.5 and 3.7 Sonnet side by side yourself. Here's a screenshot showcasing the comparison:
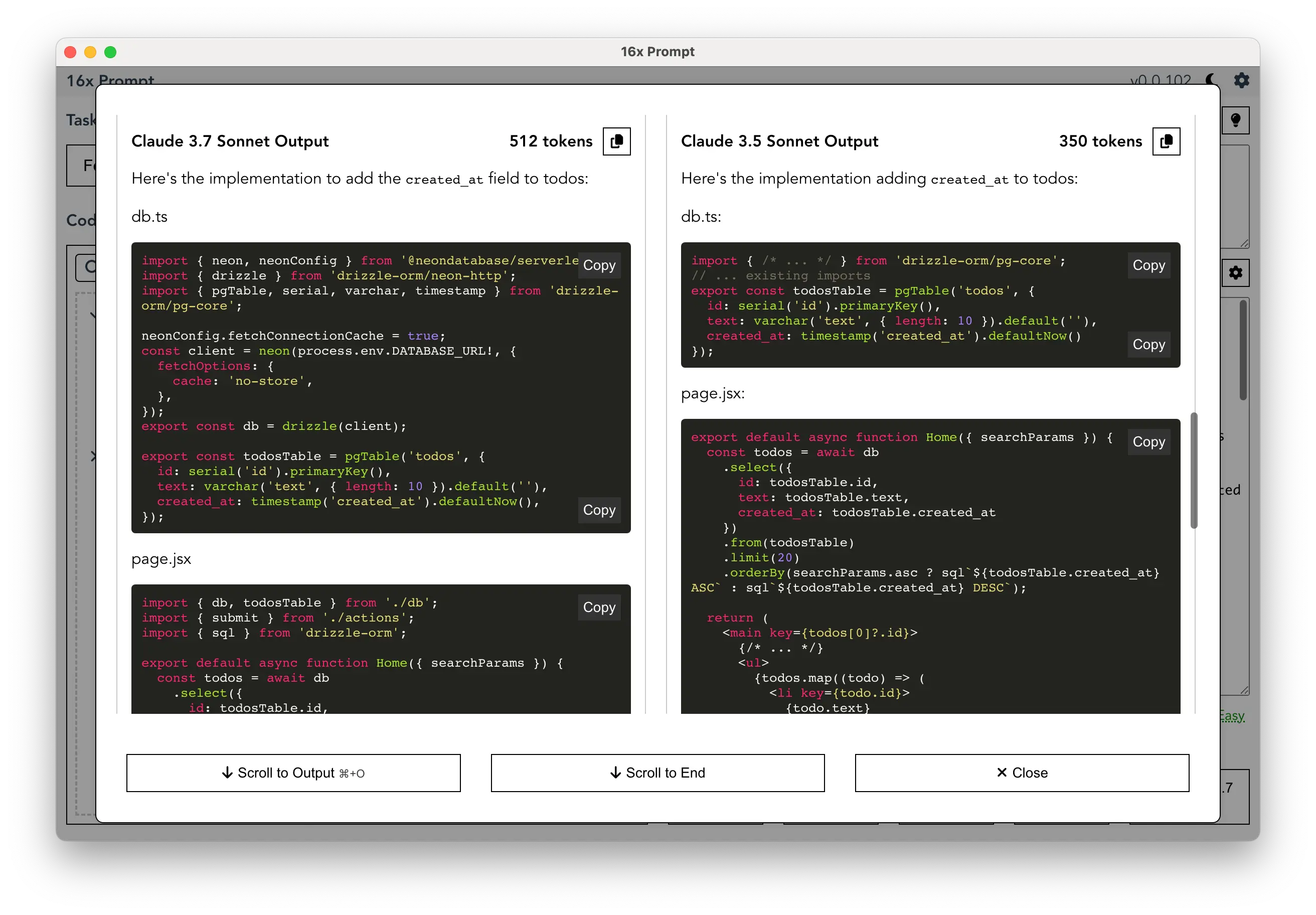
16x Prompt's code context system makes it easier to give relevant context to the model. You can copy the final prompt to the Claude website, or send it directly through the Anthropic API.