As large language models improve, their abilities are often affected by two key factors: the context window and token limit. These factors determine how much information the model can process at once. They also affect how long its responses can be.
In this post, we'll compare the latest models from OpenAI and Anthropic in terms of their context window and token limits.
Key Metrics
| Model | Context Window | Max Output |
|---|---|---|
| GPT-4o via ChatGPT | 4,096 tokens to 8,192 tokens (empirical) | 4,096 tokens to 8,192 tokens (empirical) |
| GPT-4o via API | 128k tokens | 4096 tokens |
| Claude 3.5 Sonnet | 200k tokens | 8192 tokens * |
Claude 3.5 Sonnet output token limit is 8192 in beta and requires the header
anthropic-beta: max-tokens-3-5-sonnet-2024-07-15. If the header is not specified, the limit is 4096 tokens.
- GPT-4o metrics via ChatGPT metrics based on empirical evidence.
- Claude 3.5 Sonnet metrics via Anthropic's models documentation.
- GPT-4o metrics via API based on OpenAI's model documentation and post on OpenAI forum.
Context Window Comparison
Context window refers to the amount of text or code the model can consider when generating responses.
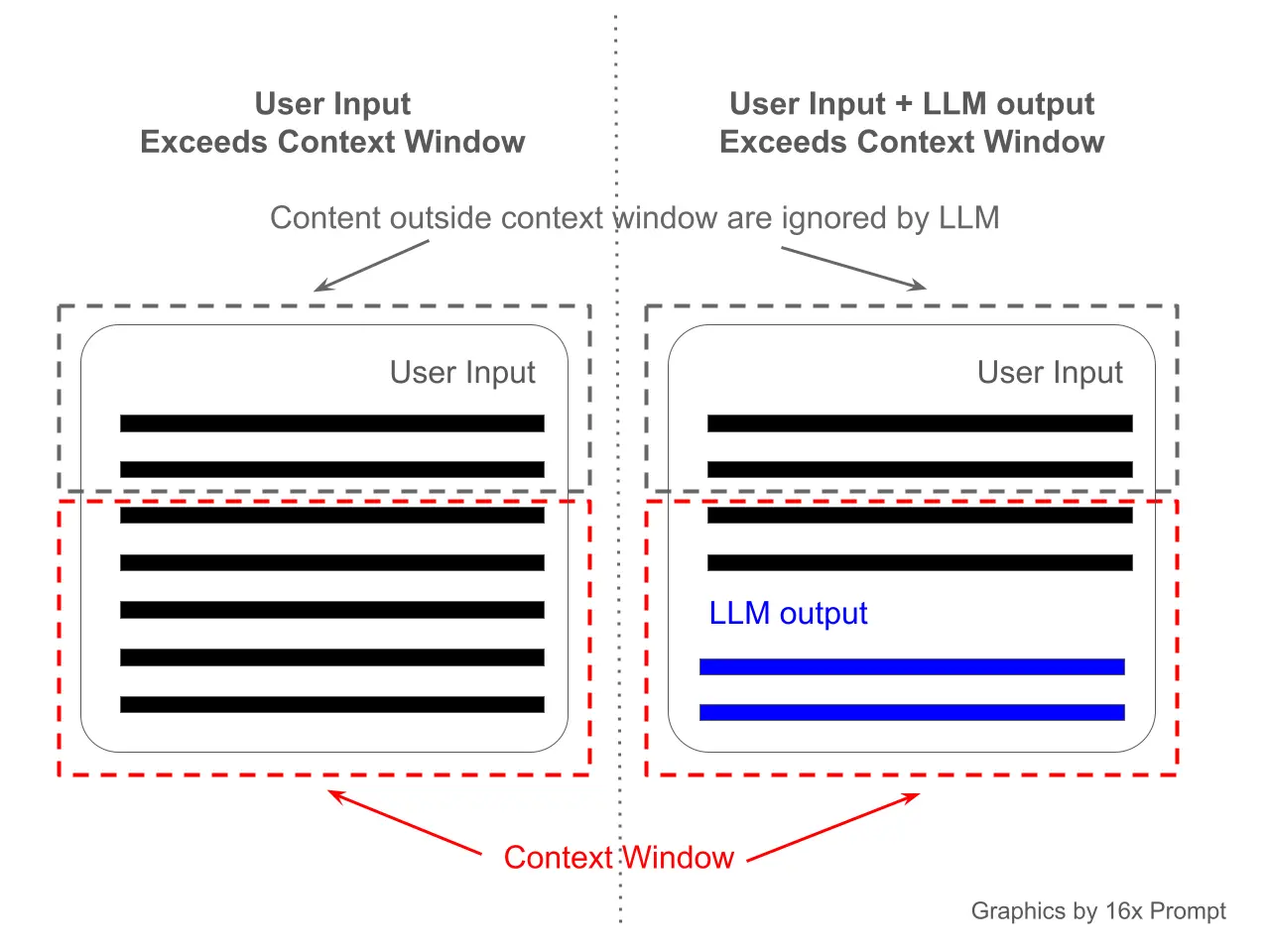
Claude 3.5 Sonnet has a large context window of 200,000 tokens. This big context window allows the model to process and consider a lot of information when generating responses. It's a big advantage for tasks that need to analyze large codebases and documents, or keep conversations coherent over long periods.
GPT-4o via API offers a context window of 128,000 tokens. While smaller than Claude 3.5 Sonnet's, it's still a big improvement over earlier models. It allows for processing large amounts of text or code.
Output Token Limits
Output token limits determine the maximum length of responses the model can generate.
For output token limits, Claude 3.5 Sonnet has a maximum output of 4,096 tokens. This means the model can generate responses up to this token limit in one interaction. It works for most standard tasks but may need breaking down very long outputs into multiple responses.
GPT-4o via ChatGPT and API does not officially specify the output token limit. However, empirical evidence suggests it ranges from 4,096 tokens to 8,192 tokens. These models from OpenAI also allow user to continue generating responses when the token limit is reached.
Applications in Software Development
For developers working with code, Claude 3.5 Sonnet and GPT-4o via API offer plenty of space.
A typical React JSX file of 200 lines is about 1,500 tokens. A Python source code file of 200 lines is around 1,700 tokens. Both models can easily handle multiple such files within their context windows.
GPT-4o via ChatGPT has a limited context window of 4,096 to 8,192 tokens. This may be a challenge for tasks requiring extensive context or long-term memory. Developers may need to chunk their inputs or manage context more effectively.
Strategies for Effective Use
To work effectively within these limits, developers can use several strategies:
-
Chunking: Break down large inputs into smaller, manageable pieces that fit within the context window.
-
Prioritizing Context: Focus on providing the most relevant information within the available token limit.
-
Iterative Interactions: For tasks needing extensive output, consider breaking them into multiple interactions with the model.
-
Code Optimization: When working with large codebases, optimize by removing unnecessary comments or whitespace to reduce token count.
16x Prompt: Enhancing Efficiency
If you use the GPT-4o or Claude 3.5 Sonnet API for coding tasks, consider using 16x Prompt as the GUI for managing your interactions. It helps you keep track of token usage, optimize input, and manage the source code context effectively.
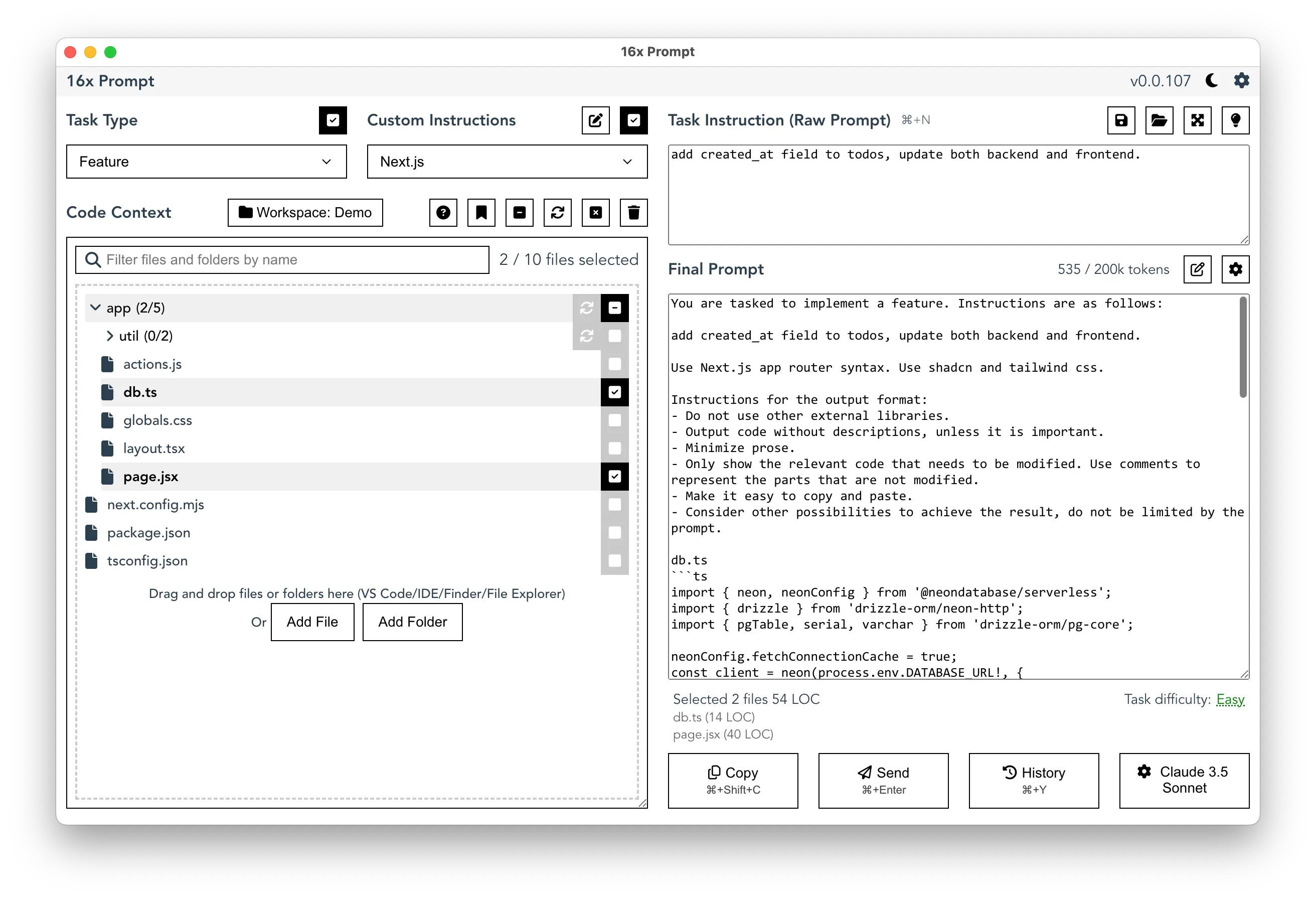
16x Prompt also works with ChatGPT or Claude web interface. You get the final prompt to copy and paste into the website. This way, you can leverage the benefits of the ChatGPT Plus or Claude Pro subscription to improve your coding workflow.