DeepSeek R1 is a new powerful reasoning model, but how much does it cost to run it? And how fast is it for daily use like coding?
Let's compare the pricing and speed of DeepSeek R1 across different providers to get a better understanding on how much it costs and how fast it is.
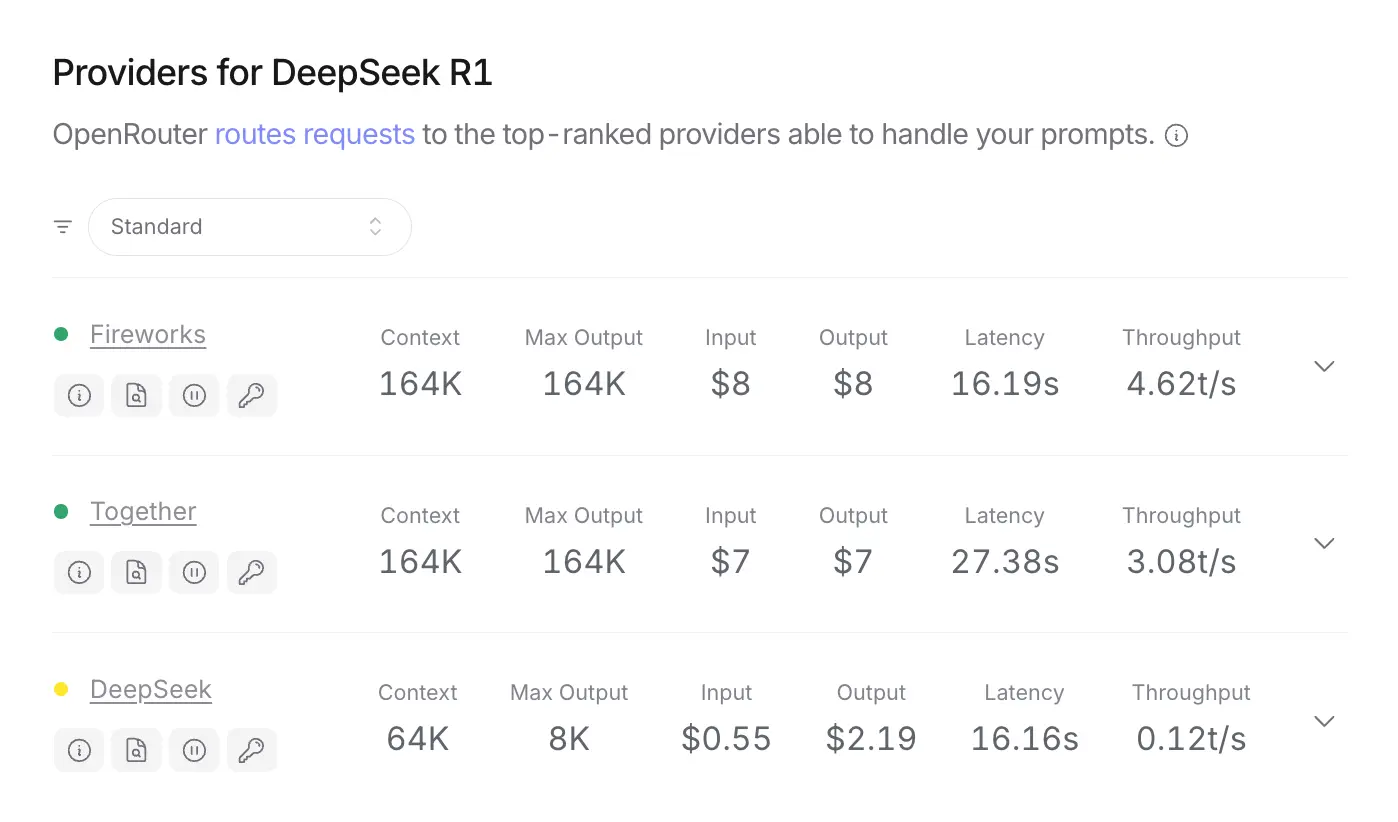
Provider Comparison
Here is a table summarizing the pricing, speed and context window of DeepSeek R1 across different providers:
| Provider | Cost per 1M tokens (Input / Output) | Historical / Latest speed Tokens/s | Context Window |
|---|---|---|---|
| DeepSeek | $0.55 / $2.19 🥇 | 34 / 18 🥇 | 64k |
| Hyperbolic (FP8) | $2.00 / $2.00 🥉 | 23 / 14 🥉 | 131k |
| Novita | $0.70 / $2.50 (turbo) 🥈 | 15 / 15 | 64k |
| Fireworks | $8.00 / $8.00 | 24 / 24 🥈 | 160k |
| Kluster (FP8) | $7.00 / $7.00 | 20 / 20 | 164k |
| Together | $7.00 / $7.00 | 17 / 17 | 164k |
| DeepInfra | $0.85 / $2.50 | 9 / 8 | 16k |
| Azure | $1.35 / 5.40 (estimated) | 6 / 6 | 128k |
| Chutes | Free via OpenRouter | - | 128k |
The speed values are median values obtained from my own benchmark tests, last updated on 21st March 2025.
Full test benchmark script and latest results are available on GitHub.
In case of a reduction in speed over time, the historical highest value is kept, and the latest median values would be lower.
Pricing
- DeepSeek official API is the cheapest with $0.55/1M input, $2.19/1M output
- It's 27x cheaper than OpenAI o1 (only 3.6% of OpenAI o1's cost)
- OpenAI o1 API pricing: $15.00/1M input, $60.00/1M output
- DeepInfra is the second cheapest with $0.85/1M input, $2.50/1M output
- However, it offers a much smaller context window
- Hyperbolic is relatively cheap with $2.00/1M for both input and output
- However, its model is quantized to FP8, which may cause quality degradation
Note that DeepSeek R1 model has F8_E4M3 (FP8 with 4-bit exponent and 3-bit mantissa) precision for most weight layers, but some layers are still in BF16 precision. It is unclear at this point if the original model weights were actually modified by Hyperbolic. You can refer to vLLM docs on FP8 for more details.
- Other providers charge significantly more
- Fireworks, Together and Kluster charge a similar price around $7 - $8/1M tokens for both input and output
- This is 9x more expensive for input tokens, and 3x more expensive for output tokens compared to DeepSeek's official pricing
- Chutes is currently free via OpenRouter, and Azure is free for now, so they are not good indicators of the real cost
Note: Reasoning models can include large number of reasoning tokens as part of the output tokens. Hence, we should only compare the cost among reasoning models (OpenAI o1, DeepSeek R1), not with other models like GPT-4o or Claude 3.5 Sonnet.
Speed
- DeepSeek API is the fastest (historical highest), 34 tokens/second (3 seconds to generate 100 tokens).
- Fireworks is the second fastest, 24 tokens/second.
- Hyperbolic is also fast at 23 tokens/second.
- Kluster, Together and Novita are also relatively fast, around 15 - 20 tokens/second.
- All other providers are very slow (less than 10 tokens/second).
For comparison:
- Claude 3.5 Sonnet speed: ~84 tokens/second (1.19 seconds to generate 100 tokens)
- GPT-4o speed: ~117 tokens/second (0.85 seconds to generate 100 tokens)
- The speed from all providers are slower than Claude 3.5 Sonnet and GPT-4o
- The fastest provider, DeepSeek API (3s), would take about 2.52x more time (3/1.19 = 2.52x) to generate the same amount of tokens compared to Claude 3.5 Sonnet (1.19s)
- This is on top of the extra time it takes for the model to think (generate the reasoning tokens)
Context Window
- Ranges from 16k (DeepInfra) to 164k (Together)
- Larger context windows are beneficial for coding tasks
- Most providers offer >100k context windows
Discussion
This comparison shows that while DeepSeek R1 offers competitive pricing through its official API, there's significant variation in pricing and performance across providers.
The current best option is to use DeepSeek official API, as it's the cheapest and fastest. The downside is that your data is sent to DeepSeek's servers and might be used for training.
Alternatively, consider using Hyperbolic, as it's cheap and offers good privacy protection. The downside is that it became slow recently, and it uses FP8 quantization, which may cause quality degradation.
If cost is not a concern, you can use Fireworks or Kluster, as they are both reasonably fast.
Note that DeepSeek R1 model has F8_E4M3 (FP8 with 4-bit exponent and 3-bit mantissa) precision for most weight layers, but some layers are still in BF16 precision. It is unclear at this point if the original model weights were actually modified by Hyperbolic. You can refer to vLLM docs on FP8 for more details.
It also raises the question of why third-party providers are charging so much more for the same model and not offering better performance:
- It could be that DeepSeek's official pricing is subsidized (below the cost of running the model), as other providers are charging significantly more
- It could also be that DeepSeek has some tricks on their side to make the model faster and cheaper
Quantized Models & OpenRouter
It is worth noting that others like bartowski and Unsloth are quantizing DeepSeek R1 further, which could make it faster and cheaper to run, by sacrificing some quality:
It is also worth mentioning that OpenRouter is an LLM API aggregator that supports DeepSeek R1 via multiple providers. You can use it to route your requests to the most cost-effective provider.
DeepSeek R1 for Coding
You can use DeepSeek R1 for coding tasks with 16x Prompt, which helps you generate optimized prompts for you to use with ChatGPT, Claude, or DeepSeek.
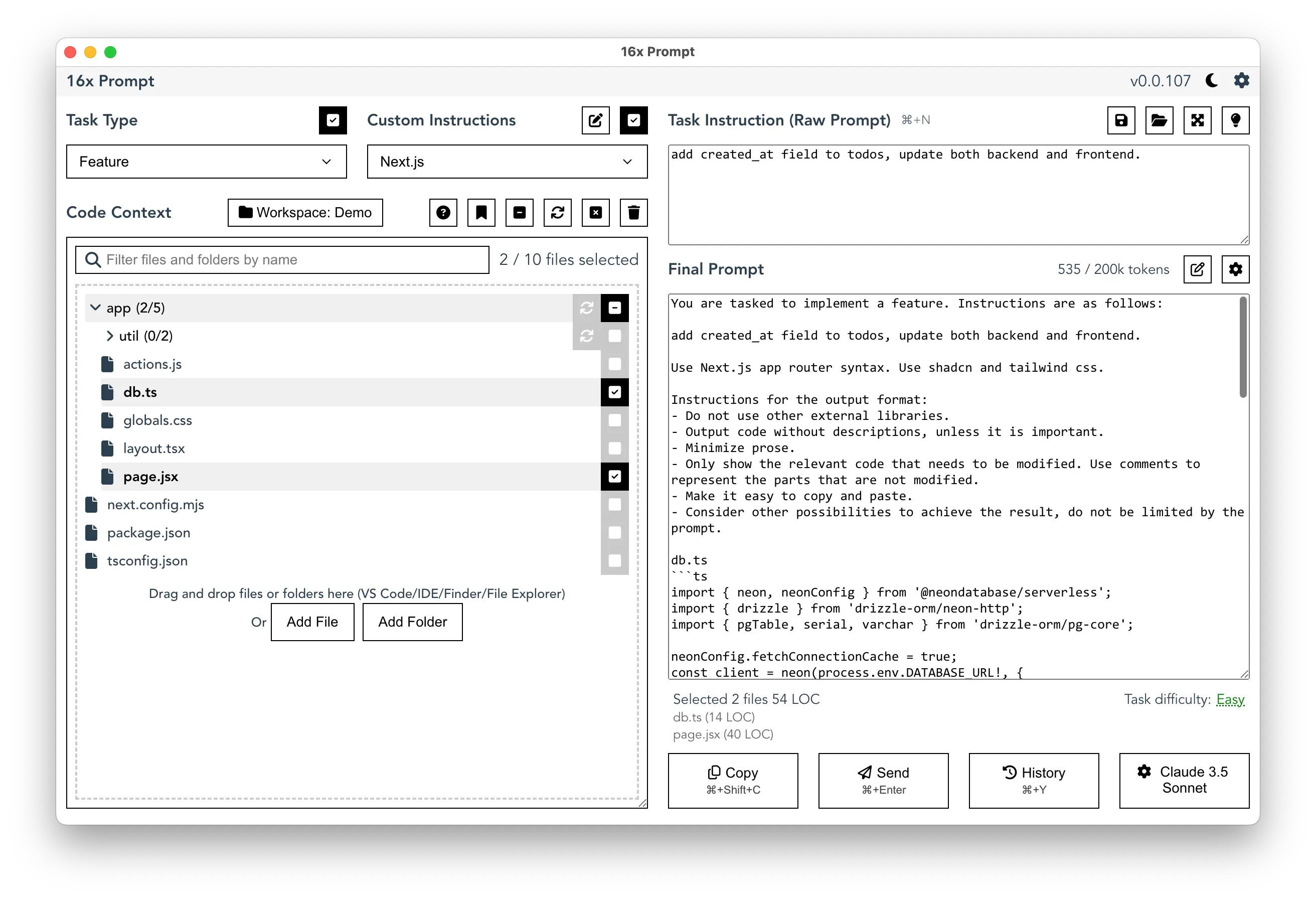
You can either copy the final prompt from 16x Prompt and paste it into any the DeepSeek web app, or send it directly to DeepSeek R1 via API.
Read more on how you can set up DeepSeek R1 API for 16x Prompt.